Don’t Starve Together – crafting tool, revisited
I haven’t played Klei’s Don’t Starve Together in quite a while, but there was an update recently which got me thinking about my DST crafting tool. With all the new additions, my data’s bound to be out of date. And even if I update it, that doesn’t really solve the problem, only delay it until the next update.
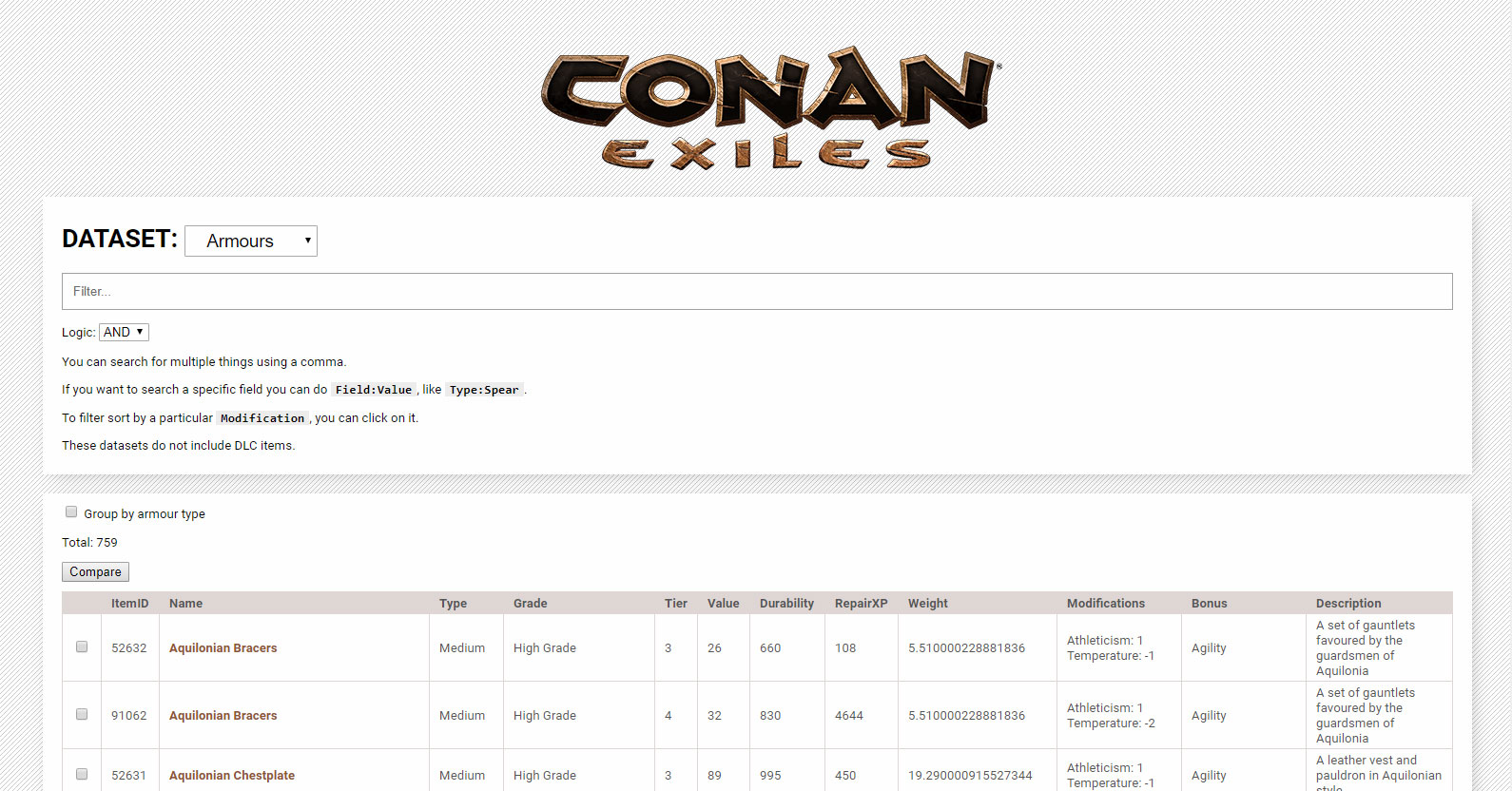
With my Conan Exiles data tool, I pulled the data directly from the game files – which I could access thanks to their modding support efforts.
Don’t Starve Together supports modding. I’ve even made mods for it. Could I do something similar there? Could I retrieve the data directly from the game files?
If I could, that’d sure help solve the issue.
Turns out I could.
Don’t Starve Together stores its data in Lua, XML, and Tex files, packaged into zip archives. So it’s not overly difficult to read the data from those files. It’s slightly more difficult to extract it in a usable format – many of the definitions reference (and arithmetically modify) other definitions.
But now I have a script for that.
So next time there’s an update, I should just be able to run that script to refresh my data. Here’s hoping.
Also, here’s a link to my don’t starve together helper tool.
It should be pretty intuitive, but click on the ? Icon for further usage instructions in any of the sections. There’s some neat stuff in there. I integrated Logipar into it.
The first two tabs (What can I make, and What do I need) should be fairly helpful. I used them a lot in their previous incarnation. The third (Recipes) less so.
I’m not clear on how the Recipes section should work, yet. Or what it should be. So I just threw something quick up, in the hope that it would help toward figuring out where it should go.